在易翻译中进行批量设置,基本流程是:先整理好待翻译的文件或表格(常见CSV、XLSX、TXT),在应用中打开“批量翻译/导入”入口,选择源语和目标语,映射文本列,设置高级选项(并发数、分批大小、保留格式、术语表等),启动翻译后下载导出结果。遇到大文件、编码或占位符问题,先预处理或使用API分块上传。

先讲清楚:批量翻译到底在做什么?
把一条一条去翻译像手工缝扣子一样慢,批量翻译就是把整箱扣子扔到机器上,一次性加工好。*关键不在于“机器更快”,而在于流程的组织*:输入格式、列映射、并发处理、术语表和导出格式,这几件事处理好了,批量就顺了。
为什么要设置批量而不是逐条翻译?
- 效率:同一格式文件一次处理,节省点击和等待。
- 一致性:能统一术语表和格式规则,减少人工校对工作。
- 可控成本:合理分批和并发可以避免突发计费和超时。
准备工作:把输入变成“机器喜欢”的样子
这一部分常被低估。想想,你去餐厅点餐,如果菜单写得一团糟,厨师也做不出满意的菜。批量翻译前先把原料准备好,能省不少麻烦。
文件格式
- 首选:CSV 或 XLSX(表格形式最易映射列)。
- 次选:纯文本(TXT),按行分句或按特殊分隔符分段。
- 注意编码:统一用 UTF-8,避免乱码。
列与字段
推荐把需要翻的文本放在单独一列(比如“原文”),翻译结果导出到另一列(比如“译文”)。如果有上下文列(备注、类型、ID),一起导入可以提高翻译质量。
占位符与标签处理
像{username}、%s、HTML标签这类占位符要提前标记或保护,告诉翻译引擎“别动它”。否则译文可能把占位符拆开,造成替换失败。
移动端操作流程(通用步骤说明)
手机界面通常更简洁,步骤大同小异,写下来以便照着做:
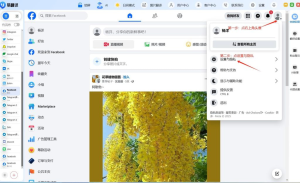
- 打开易翻译,找到主界面的“批量翻译”或“导入”按钮。
- 选择要上传的文件(从本地、云盘或分享打开)。
- 选择源语言和目标语言,或开启自动检测(适合混语料)。
- 映射列:告诉软件哪一列是原文,哪一列要接收译文。
- 配置高级选项(并发、分批、保留格式、术语表),如果不懂默认即可。
- 点击开始/翻译,等待进度完成,下载或保存结果到本地/云盘。
桌面/网页版操作流程(更细化、更适合大文件)
网页版通常支持更大文件和更丰富的高级选项,推荐用于企业批量处理。
- 打开网页端,进入“批量翻译”模块。
- 上传文件(拖拽或选择)。注意文件大小限制,超大文件建议分块上传。
- 在字段映射界面,选定“原文列”和“译文列”,可以预览几行数据确认映射无误。
- 选择翻译引擎或模式(机器、机器+人工后校、或调用公司记忆库)。
- 修改高级参数,然后提交任务。可查看任务队列与日志。
示例:CSV 列映射小表(示意)
| CSV 列名 | 作用 | 映射到易翻译 |
| ID | 记录标识,不翻译 | 保留(作为参考列) |
| 原文 | 需要翻译的文本 | 映射为“原文”列 |
| 上下文 | 备注或上下文信息 | 作为辅助列导入(提升译文质量) |
| 译文 | 输出列,初为空 | 映射为“译文”列,翻译后填充 |
高级选项详解(抓住这几点就行)
| 选项 | 作用 |
| 并发数 | 同时处理多少条/多少文件,影响速度与API配额 |
| 分批大小 | 把文件拆成多批次上传,防止单次超时或卡住 |
| 保留格式 | 保留HTML、Markdown或占位符不被翻译,必要时勾选 |
| 术语表/强制词汇 | 制定行业专有名词,保证一致性 |
| 翻译记忆(TM) | 使用历史翻译提高一致性并节约成本 |
常见问题与解决方法(实操为王)
- 乱码:先确认文件是UTF-8编码,必要时用文本编辑器另存为UTF-8。
- 列映射出错:上传后预览几行,确认列索引和列名是否与预期一致。
- 占位符被翻译或拆分:在导入前把占位符包在特殊标签里或勾选“保留格式”。
- 文件太大:分批上传或使用API分块提交。
- 翻译不一致:上传术语表或启用翻译记忆。
错误日志如何读
任务失败通常会返回错误码和行号:行号告诉你哪一条数据卡住了,错误码提示是超时、格式还是配额问题。看到“超时/网络错误”先重试或降低并发;看到“格式错误”回到原文件检查那一行。
当数据量极大时,用API会更稳妥
如果有数万、数十万条记录,网页版上传很容易受限。通过API可以做到:
- 分片上传(把大文件拆成多段)
- 并发控制与重试机制
- 在后端批处理并与内部系统对接
注意API也有速率限制和计费策略,做批量前先看清文档和配额。
实践小技巧(这些能节省大量时间)
- 预处理:去掉多余空行、修正错别字、清理特殊符号。
- 先试点:先翻一小批(比如100条)确认术语和格式,再放量。
- 分批大小:对网络不稳的环境,分批大小设置小一些更可靠。
- 保留原列:不要覆盖原文列,导出时把译文放新列,便于比对回滚。
- 日志保留:保留每次任务的日志,遇问题能快速定位。
如果你只是偶尔批量翻几百条,最省心的做法
使用手机或网页版的“批量翻译”入口,按默认设置上传CSV/XLSX,勾选“保留格式”和“术语表”(如果有),先跑一小批预览,确认无误后一键全量翻译。省时省力,出错也容易回退。
好吧,这些就是我在做批量翻译时常用的套路:把原料准备好、映射好列、保护占位符、合理分批和并发、必要时走API。你可能会根据实际界面名称找到稍有不同的按钮,但思路差不多——按这个顺序走,绝大多数问题都能提前避免。随手试几次,你会越做越顺手。